🐋 How DeepSeek slayed the AI giants https://substack.tech-talk-cto.com/p/how-deepseek-disrupted-the-ai-giants
Data points are sourced from
- https://arxiv.org/pdf/2412.19437v1
- openai.com/index/gpt-4-research/
- wired.com/story/openai-ceo-sam-altman-the-age-of-giant-aimodels-is-already-over/
- api-docs.deepseek.com/quick_start/pricing
- help.openai.com/en/articles/7127956-how-much-does-gpt-4-cost
- https://arxiv.org/pdf/2407.21783
- apxml.com/posts/training-cost-deepseek-v3-vs-llama-3
- together.ai/pricing
https://www.linkedin.com/posts/alexxubyte_systemdesign-coding-interviewtips-activity-7291148447385079809--39I?utm_source=sharehttps://www.linkedin.com/posts/alexxubyte_systemdesign-coding-interviewtips-activity-7291148447385079809--39I?utm_source=share&utm_medium=member_desktoputm_medium=member_desktop
1 - DeepSeek-R1 uses a Mixture-of-Experts (MoE) architecture with 671 billion total parameters, activating only 37 billion parameters per task.
2 - It employs selective parameter activation through MoE for resource optimization.
3 - The model is pre-trained on 14.8 trillion tokens across 52 languages.
4 - DeepSeek-R1 was trained using just 2000 Nvidia GPUs. By comparison, ChatGPT-4 needed approximately 25K Nvidia GPUs over 90-100 days.
5 - The model is 85-90% more cost-effective than competitors.
6 - It excels in mathematics, coding, and reasoning tasks.
7 - Also, the model has been released as open-source under the MIT license.
Hardware
https://x.com/carrigmat/status/1884244369907278106
Complete hardware + software setup for running Deepseek-R1 locally. The actual model, no distillations, and Q8 quantization for full quality. Total cost, $6,000. All download and part links below:
RAM: This is the big one. We are going to need 768GB (to fit the model) across 24 RAM channels (to get the bandwidth to run it fast enough). That means 24 x 32GB DDR5-RDIMM modules. Example kits:
And finally, the SSD: Any 1TB or larger SSD that can fit R1 is fine. I recommend NVMe, just because you'll have to copy 700GB into RAM when you start the model, lol. No link here, if you got this far I assume you can find one yourself!
Yes, there's no GPU in this build! If you want to host on GPU for faster generation speed, you can! You'll just lose a lot of quality from quantization, or if you want Q8 you'll need >700GB of GPU memory, which will probably cost $100k+
With 768GB, I don't think context length will be a limit. The model is 650GB, so you have another ~100GB for KV caches. You'll probably get to about 100k (?) tokens before running out of memory
Yes, this is the full 670B model at Q8 quantization, so quality should be indistinguishable from the Deepseek API
Memory bandwidth is everything. The system I linked here has about 1TB/sec of bandwidth and generates 6-8tokens/second, so you can estimate the speed you get from that - e.g. if your system has 250GB/sec of bandwidth, then you can expect 1.5 - 2 tok/second.
At 8 channels, you could try a Threadripper or Xeon motherboard, and at Q4 you could run with 384GB of RAM, so 8 x 48GB sticks. I'd estimate the cost would still be $3000-$4000, and the speed would be maybe ~4 tokens per second.
The model itself may refuse some questions, depending on how it was trained, but there is no additional filtering layer between you and the model outputs
And if you got this far: Yes, there's no GPU in this build! If you want to host on GPU for faster generation speed, you can! You'll just lose a lot of quality from quantization, or if you want Q8 you'll need >700GB of GPU memory, which will probably cost $100k+
](https://x.com/carrigmat/status/1884247727758008642))
](https://x.com/carrigmat/status/1884275617480466901))
Deepseek
- https://www.deepseek.com/
- DeepSeek R1 Explained to your grandma https://www.youtube.com/watch?v=kv8frWeKoeo
- https://x.com/lmarena_ai/status/1882875989610594542
- DeepSeek releases Janus Pro, a text-to-image generator [pdf] https://news.ycombinator.com/item?id=42843131
- Deepseek: The Quiet Giant Leading China’s AI Race [https://www.chinatalk.media/p/deepseek-ceo-interview-with-chinas](https://www.chinatalk.media/p/deepseek-ceo-interview-with-chinas)
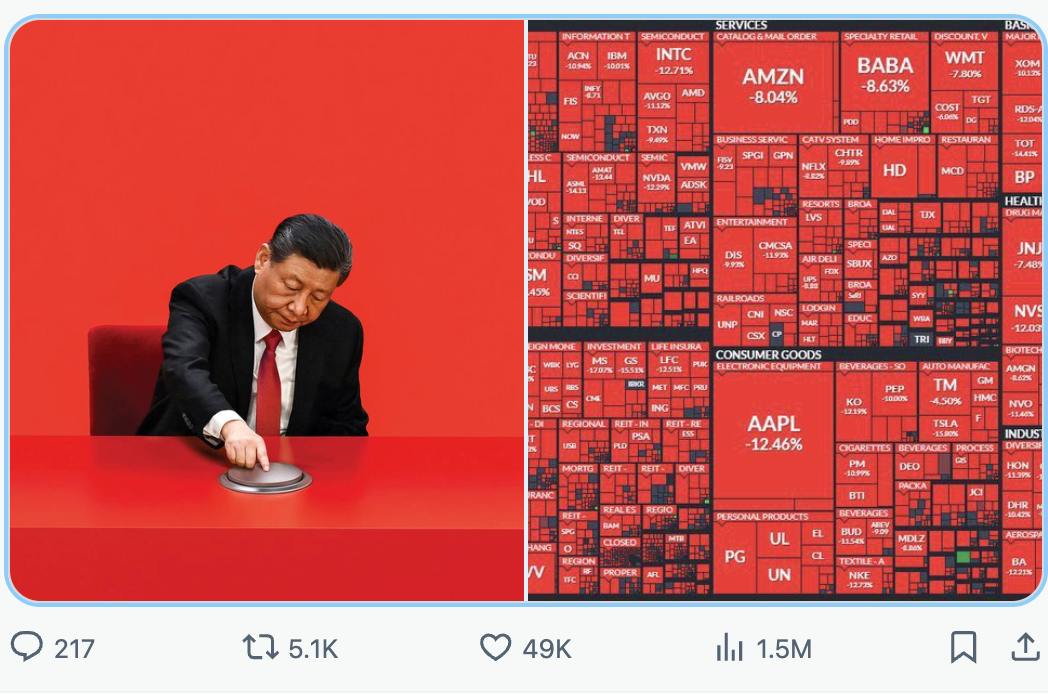
- Spend billions to make good Al model
- Tell the west it only cost $6m
- OPEN Short on $NVDA
- Cause panic + profit
- Raise funds to actually buy more GPUs
Meme
- Big Tech in panic mode... Did DeepSeek R1 just pop the AI bubble? https://www.youtube.com/watch?v=Nl7aCUsWykg
- Ying Yang at bloomberg - Silicon Valley https://www.youtube.com/watch?v=t863n1d1ol0
#zeroread #ml
@GavinSBaker
https://x.com/GavinSBaker/status/1883891311473782995
DeepSeek r1 is real with important nuances. Most important is the fact that r1 is so much cheaper and more efficient to inference than o1, not from the $6m training figure. r1 costs 93% less to use than o1 per each API, can be run locally on a high end work station and does not seem to have hit any rate limits which is wild. Simple math is that every 1b active parameters requires 1 gb of RAM in FP8, so r1 requires 37 gb of RAM. Batching massively lowers costs and more compute increases tokens/second so still advantages to inference in the cloud. Would also note that there are true geopolitical dynamics at play here and I don’t think it is a coincidence that this came out right after “Stargate.” RIP, $500 billion - we hardly even knew you.
Real: 1) It is/was the #1 download in the relevant App Store category. Obviously ahead of ChatGPT; something neither Gemini nor Claude was able to accomplish. 2) It is comparable to o1 from a quality perspective although lags o3. 3) There were real algorithmic breakthroughs that led to it being dramatically more efficient both to train and inference. Training in FP8, MLA and multi-token prediction are significant. 4) It is easy to verify that the r1 training run only cost $6m. While this is literally true, it is also deeply misleading. 5) Even their hardware architecture is novel and I will note that they use PCI-Express for scale up.
Nuance:
- The $6m does not include “costs associated with prior research and ablation experiments on architectures, algorithms and data” per the technical paper. “Other than that Mrs. Lincoln, how was the play?” This means that it is possible to train an r1 quality model with a $6m run if a lab has already spent hundreds of millions of dollars on prior research and has access to much larger clusters. Deepseek obviously has way more than 2048 H800s; one of their earlier papers referenced a cluster of 10k A100s. An equivalently smart team can’t just spin up a 2000 GPU cluster and train r1 from scratch with $6m. Roughly 20% of Nvidia’s revenue goes through Singapore. 20% of Nvidia’s GPUs are probably not in Singapore despite their best efforts.
- There was a lot of distillation - i.e. it is unlikely they could have trained this without unhindered access to GPT-4o and o1.
As @altcap pointed out to me yesterday, kinda funny to restrict access to leading edge GPUs and not do anything about China’s ability to distill leading edge American models - obviously defeats the purpose of the export restrictions. Why buy the cow when you can get the milk for free?
Conclusions:
- Lowering the cost to train will increase the ROI on AI.
- There is no world where this is positive for training capex or the “power” theme in the near term.
- The biggest risk to the current “AI infrastructure” winners across tech, industrials, utilities and energy is that a distilled version of r1 can be run locally at the edge on a high end work station (someone referenced a Mac Studio Pro). That means that a similar model will run on a superphone in circa 2 years. If inference moves to the edge because it is “good enough,” we are living in a very different world with very different winners - i.e. the biggest PC and smartphone upgrade cycle we have ever seen. Compute has oscillated between centralization and decentralization for a long time.
- ASI is really, really close and no one really knows what the economic returns to superintelligence will be. If a $100 billion reasoning model trained on 100k plus Blackwells (o5, Gemini 3, Grok 4) is curing cancer and inventing warp drives, then the returns to ASI will be really high and training capex and power consumption will steadily grow; Dyson Spheres will be back to being best explanation for Fermi’s paradox. I hope the returns to ASI are high - would be so awesome.
- This is all really good for the companies that use AI: software, internet, etc.
- From an economic perspective, this massively increases the value of distribution and unique data - YouTube, Facebook, Instagram and X.
- American labs are likely to stop releasing their leading edge models to prevent the distillation that was so essential to r1, although the cat may already be entirely out of the bag on this front. i.e. r1 may be enough to train r2, etc.
Grok-3 looms large and might significantly impact the above conclusions. This will be the first significant test of scaling laws for pre-training arguably since GPT-4. In the same way that it took several weeks to turn v3 into r1 via RL, it will likely take several weeks to run the RL necessary to improve Grok-3’s reasoning capabilities. The better the base model, the better the reasoning model should be as the three scaling laws are multiplicative - pre-training, RL during post-training and test-time compute during inference (a function of the RL). Grok-3 has already shown it can do tasks beyond o1 - see the Tesseract demo - how far beyond is going to be important. To paraphrase an anonymous Orc from “The Two Towers,” meat might be back on the menu very shortly. Time will tell and “when the facts, I change my mind.”
DeepSeek founder and CEO Liang Wenfeng
[https://www.chinatalk.media/p/deepseek-ceo-interview-with-chinas](https://www.chinatalk.media/p/deepseek-ceo-interview-with-chinas)
This interview with DeepSeek founder and CEO Liang Wenfeng, also co-founder of the hedge fund backing DeepSeek, might shed some light on the
Some relevant excerpts:
“Because we believe the most important thing now is to participate in the global innovation wave. For many years, Chinese companies are used to others doing technological innovation, while we focused on application monetization — but this isn’t inevitable. In this wave, our starting point is not to take advantage of the opportunity to make a quick profit, but rather to reach the technical frontier and drive the development of the entire ecosystem.”
“We believe that as the economy develops, China should gradually become a contributor instead of freeriding. In the past 30+ years of the IT wave, we basically didn’t participate in real technological innovation. We’re used to Moore’s Law falling out of the sky, lying at home waiting 18 months for better hardware and software to emerge. That’s how the Scaling Law is being treated.
“But in fact, this is something that has been created through the tireless efforts of generations of Western-led tech communities. It’s just because we weren’t previously involved in this process that we’ve ignored its existence.”
“We do not have financing plans in the short term. Money has never been the problem for us; bans on shipments of advanced chips are the problem.”
“In the face of disruptive technologies, moats created by closed source are temporary. Even OpenAI’s closed source approach can’t prevent others from catching up. So we anchor our value in our team — our colleagues grow through this process, accumulate know-how, and form an organization and culture capable of innovation. That’s our moat.
“Open source, publishing papers, in fact, do not cost us anything. For technical talent, having others follow your innovation gives a great sense of accomplishment. In fact, open source is more of a cultural behavior than a commercial one, and contributing to it earns us respect. There is also a cultural attraction for a company to do this.”
Quality
Surprisingly, 99% of the code in this PR is written by DeekSeek-R1. The only thing I do is to develop tests and write prompts (with some trials and errors)